
Predicting future trends from past novelty: New model for trend estimation on social media
As part of the H2020-project NGI Forward, DATALAB has developed a new model for the estimation of trend reservoirs. The model was applied on the social media site Reddit to deliver insights into trending discussions on artificial intelligence.

Sociocultural trends from social media platforms have become an important part of knowledge discovery. The growth of social media usage over the last decade has opened up a data trove for researchers to analyse patterns in communication, allowing them to gain insights into new trends or emerging issues.
For policy makers, insights into emerging trends can be of great value when crafting policy or regulatory responses to new developments - especially in the realm of internet technology where the development is rapid and complex dilemmas can emerge. As part of the H2020-project, DATALAB was tasked to deliver insights into internet-related tech trends on social media to help the European Commission identify the most important technologies and issues to be at the center of their ambitious Next Generation Internet initiative.
A new approach to social media trend estimation
Accurate trend estimation on social media is however a matter of debate in the research community. Standard approaches often suffer from several methodological issues by focusing solely on spiky behavior and thus equating trend detection with that of natural catastrophes and epidemics.
To remedy these problematic issues our team at DATALAB developed a new approach to trend estimation that combines domain knowledge of social media with advances in information theory and dynamical systems. In particular, trend reservoirs, i.e. signals that display trend potential, are identified by their relationship between novel and resonant behavior, and their minimal persistence.
The model estimates Novelty as a reliable difference from the past – how much does the content diverge from the past – and Resonance as the degree to which future information conforms to the Novelty – to what degree does the novel content ‘stick’. Using calculations of Novelty and Resonance, trends are then characterized by a strong Novelty-Resonance association and long-range memory in the information stream. Results show that these two ‘signatures’ capture different properties of trend reservoirs, information stickiness and multi-scale correlations respectively, and they both have discriminatory power, i.e. they can actually detect trend reservoirs.
Case study: AI discussions on Reddit
To exemplify the application of the model for trend estimation, it is applied on the social media site Reddit to discover innovative discussions related to artificial intelligence (AI).
Reddit hosts discussions about text posts and web links across hundreds of topic-based communities called “subreddits” that often target specialized expert audiences on these topics. Topically defined discussions are thus an important part of the appeal of Reddit, unlike the information dissemination focus of Twitter, and the specialized audiences make it a promising source for topical discussions on, for example, internet technology.
The most trending subreddits are discovered using the model on a sample of subreddits with the highest overlap between their descriptions and a seed list of AI-related terms. The top 10 most relevant subreddits in terms of content matching can be found in the table below in two categories: Leaders and Prospects. The Leaders are subreddits with a substantial number of posts (more than 2560), while the Prospects are subreddits that can be small but rank the highest on the content matching.
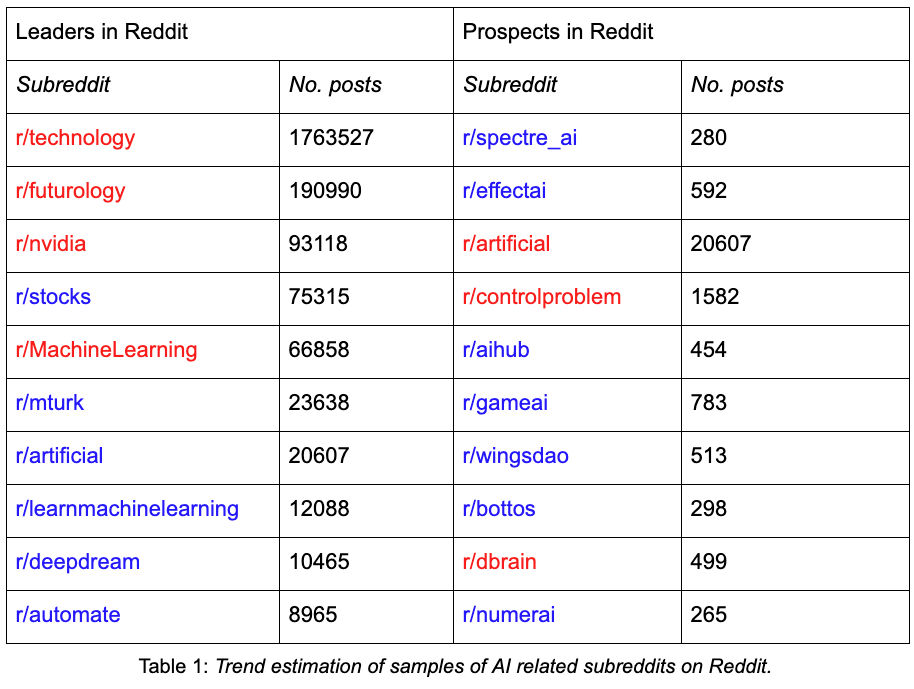
We can then use the trend estimation model to classify into maximally trending and just trending or not trending. In the table above, the red subreddits are classified as maximally trending while blue are not. In the Leaders category, subreddits will have to be trending based on both signatures, i.e. having a strong Novelty-Resonance association and displaying long-range memory, to qualify as maximally trending. Prospects can qualify as maximally trending with only one of the two signatures.
Leaders are relevant because of the many posts of potentially trending content, while Prospects can be used to discover singular new trends. A recommender engine can be trained with this classifier to identify trending subreddits within any given subject. Such classifications can be extremely useful for decision support in terms of which subreddits to follow for a continuum of information on trends in e.g. AI.
After the classification, the content on the most trending subreddits can be explored. To do this, we training a neural embedding model to query the highest-ranking words and their associated words, providing insights into e.g. the contexts in which the technologies are discussed.
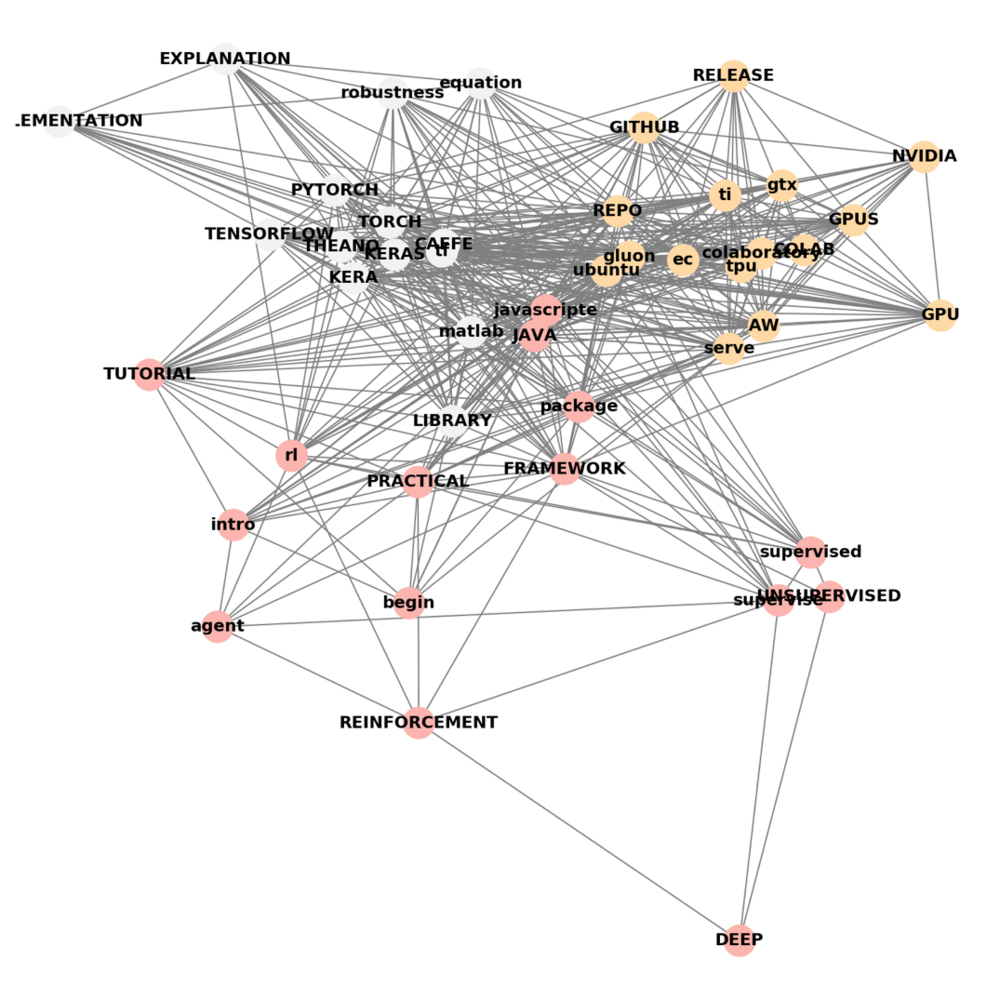
This method of content exploration produces concepts graphs as the one above of words used in the subreddit and their associations. The graph above is a concept graph from the trending subreddit r/MachineLearing - we can call the graph TOOL-DIVERSIFICATION. As data science and machine learning are complicated fields, many classes of tools are necessary to develop state-of-the-art deep learning models, and the concept graph shows three clusters of interest:
- The upper right corner shows important tools related to “Hardware and Cloud” technologies (NVIDIA, GPU, TPU, AWS, server, Ubuntu, Gluon), which are all characteristics of GPU accelerated high performance computing;
- The cluster in the center left of the graph is dominated by the most important deep learning “Software Libraries” in Python (Tensorflow, PyTorch, Keras, Theano) and related languages (JavaScript, Java, Caffe MATLAB);
- In the lower part, the graph displays “Classes of Problems” (supervised, unsupervised, reinforcement learning).
Two further observations can be made. Firstly, “Tutorial” is highly interconnected to all clusters, supporting the fact that tutorials have become one of the primary sources of assimilating the diverse tools in the machine learning community. Secondly, software libraries, packages, and frameworks take a central role in the graph. They all signify bundles of preexisting code that minimize the amount of programming and hardware understanding required by machine learning enthusiasts.
These observations indicate that the subreddit does not consist of solely professional machine learning developers, but rather constitutes a community of machine learning enthusiasts with a do-it-yourself approach to machine learning.
This is just an example of the content that can be extracted after identifying the most trending subreddits within the topic of investigation with the model for trend estimation. This approach to the estimation of trend reservoirs generalizes to other data sources, such as Twitter, and other data types, such as images.